En el anterior post vimos cómo instalar y configurar nginx con caché y cómo comprobar el rendimiento. En este post me voy a centrar en cómo no servir contenido obsoleto.
Refrescando la caché
Lógicamente si la caché dura un día, los usuarios tardarán un día desde que envían un mensaje hasta que se pueda ver. Incluso ellos mismos no verían su mensaje, lo que es muy confuso.
Sin caché, estaríamos hablando entre 1000 y 2000 por segundo, que también es muy rápido. Como el backend sólo realiza una tarea muy básica, le permite entregar una cantidad de peticiones muy alta. Gracias a esto, podemos permitirnos que las cachés sean más pequeñas si queremos, ya que el tiempo de generar el contenido es realmente bajo.
Podemos establecer unos tiempos de caché distintos según el tipo de contenido que sea. Por ejemplo para los foros puede ser bastante largo. Para los hilos un tiempo intermedio y para los mensajes sería más corto.
Es más, como el backend puede devolver para cada petición unas cabeceras de control de caché distintas, podemos hacer que los hilos viejos y los mensajes viejos que tienen menos probabilidad de cambiar, que tengan una caché más grande. Especialmente las páginas de mensajes que tienen más de un par de días. Si tenemos bloqueadas las ediciones pasado un tiempo, ya tenemos garantizado que éstos no cambian.
El contenido que puede cambiar, la caché como mucho va a ser de escasos segundos. Y a veces incluso eso va a ser mucho en algunos casos ya que la aplicación podría pedir el post que se acaba de escribir y no lo vería.
Para solucionar eso lo ideal es que al realizar la petición PUT/POST desde javascript, el servidor devuelva el JSON entrada con él y lo integre. De ese modo una caché de unos pocos segundos no le afecta y ve el contenido instantáneamente. Los demás tardarán un poco, por ejemplo 5 segundos.
Pero esto quiere decir que si un hilo recibe mucha actividad, vamos a tener muchos usuarios leyendo la última página y refrescando. Cada poco, vamos a tener que generar una versión nueva. La ventaja es que la caché de 5 segundos va a enviar la misma copia a varias personas, por lo que la carga ya se va a reducir muchísimo.
Pero esto se puede mejorar aún más.
304 Revalidate con NGINX
En NGINX se puede habilitar una opción de caché llamada “revalidate“, que cuando la caché caduca, envía al servidor una petición con E-Tag y/o If-Modified-Since, y el servidor puede responder con HTTP 304 Not Modified. Si esto sucede, NGINX renueva la caché. Ésta respuesta “Not Modified” deberá tener también las cabeceras Cache-Control y en ellas podemos incluso definir nuevos parámetros de persistencia si queremos.
Supongo que sabéis cómo funciona: En cada petición en el backend generamos o una fecha de modificación, o un string (tipo una firma) llamado E-Tag. Cuando el cliente web nos envía una petición para la que ya tiene caché, incluye éstos parámetros y podemos comparar si su versión es aún válida o la hemos cambiado. Si ha cambiado o no provee éstas cabeceras, realizamos la petición normal y devolvemos HTTP 200. Si no ha cambiado, devolvemos HTTP 304, sin contenido.
Para hacer esto en Nginx es tan sencillo como activar cache_revalidate:
uwsgi_cache_revalidate on;
La ventaja de esto es que no tenemos que generar el contenido otra vez y no tenemos que enviarlo. El truco reside en encontrar la forma de saber si ha cambiado sin apenas usar recursos. Si en la base de datos tenemos una fecha de modificación, podemos usar esa. También se puede usar redis u otro sistema de caché en memoria para almacenar la versión y actualizarla cada vez que envíen contenido nuevo.
También está cache_lock que es interesante. Si se activa, cuando llegan dos peticiones para la misma página y no tiene caché, sólo lanza una petición al backend y la segunda petición se espera. Muy útil para evitar consumo de recursos extra a costa de que el cliente espere un poco. De todos modos es muy posible que la primera petición termine antes que la segunda, por lo que no debería haber ningún retraso percibido, con la ventaja de consumir menos:
uwsgi_cache_lock on;
Volvamos a revisar la gráfica que hice al principio:
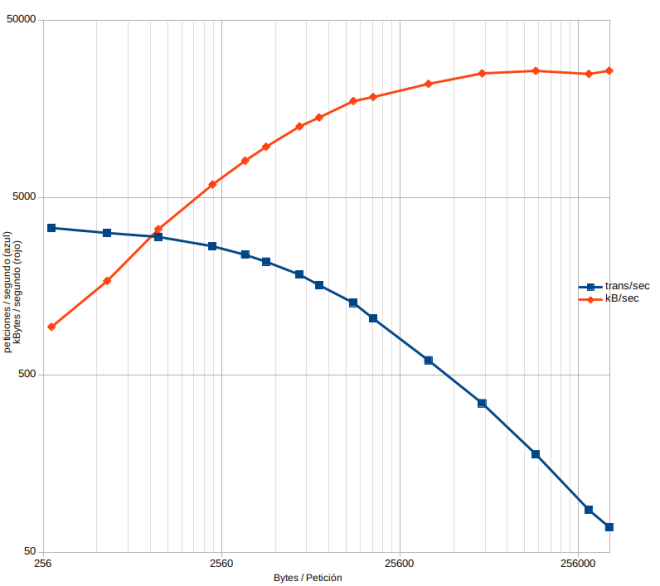
En el extremo izquierdo hay 3000 peticiones por segundo para las consultas que no pesan casi nada, y en el derecho unas 300 por segundo para las que ya tienen un tamaño considerable. Esto quiere decir que para contenido grande, podemos hacer que NGINX lo mantenga en caché a un ritmo 10 veces más rápido que generarlo de nuevo! Es como una caché sin caché. O caché inteligente.
Incluso podría ser mejor. Puede que haya contenido que requiera mucha lógica para computarlo aunque no pese demasiado. Este contenido se beneficiaría aún más de ésta práctica.
Con éste sistema, la caché se puede bajar hasta 1 segundo y el ritmo de entrega sigue siendo muy bueno. Aún así, hay que seguir considerando el cachear más tiempo el contenido que no va a cambiar, porque aún es tres veces más rápido que el 304.
Hago la prueba con caché de 1 segundo, gestión del 304 y a medir con siege:
$ siege -f urls3.txt -c 8 -ib -t 60s (...) Lifting the server siege... Transactions: 216952 hits Availability: 100.00 % Elapsed time: 59.61 secs Data transferred: 242.55 MB Response time: 0.00 secs Transaction rate: 3639.52 trans/sec Throughput: 4.07 MB/sec Concurrency: 7.46 Successful transactions: 216952 Failed transactions: 0 Longest transaction: 0.27 Shortest transaction: 0.00
Como vemos, llego a las 3639 peticiones por segundo. Es decir, a pesar de servir un contenido que me daba 2500, se sirve a una velocidad altísima. Y como comentaba, si el tamaño de la respuesta aumenta, ésta velocidad no se reduce apenas porque estamos devolviendo sólo un 304. El truco es devolver el 304 rápidamente, en mi caso siempre lo hago sin ningún cálculo por lo que es de esperar que en una web real haya que calcular un poco.
Métodos de refresco forzado
Aún se puede mejorar más, pues NGINX tiene otras opciones de interés. Una es el stale-while-revalidate, que hace que entregue a los clientes una copia antigua enseguida mientras él la actualiza por debajo.
proxy_cache_use_stale updating error timeout http_500
http_502 http_503 http_504;
proxy_cache_background_update on;
Al hacer estos cambios y probar, ya veo un aumento en el rendimiento:
Transactions: 239757 hits Availability: 100.00 % Elapsed time: 59.72 secs Data transferred: 267.79 MB Response time: 0.00 secs Transaction rate: 4014.69 trans/sec Throughput: 4.48 MB/sec Concurrency: 7.43 Successful transactions: 239758 Failed transactions: 0 Longest transaction: 0.23 Shortest transaction: 0.00
El problema de esto es que no podemos especificar cuan vieja puede llegar a ser la caché, por lo que aunque nuestra caché sea de 1 segundo, si durante una hora nadie la pide, el siguiente que la pida verá la de hace una hora y se actualizará en segundo plano.
Si queremos corregir esto, en lugar de usar estos comandos hay que usar las cabeceras http Cache-Control con stale-while-revalidate y stale-if-error, que permiten especificar el máximo de tiempo. Pero no estoy seguro de si Nginx sigue los tiempos también.
Otra de las opciones es purgar la caché a demanda. Se puede hacer que al recibir ciertas peticiones nginx vacíe la caché. Primero establecemos que cuando se reciba una petición tipo PURGE nos asigne una variable a 1:
map $request_method $purge_method { PURGE 1; default 0; }
Luego asignamos este $purge_method como flag al comando cache_purge:
uwsgi_cache_purge $purge_method;
Esto resulta en que cuando se recibe una petición de tipo PURGE, la url especificada se elimina de la caché. También acepta patrones, por lo que se puede hacer:
$ curl -X PURGE -D – "https://www.example.com/api/forums/1/*"
Otra opción son URLs que no leen de caché, pero sí guardan. Lo normal es que si una URL guarda a la caché, también lea de la caché. Y que si no lee, tampoco guarde. Esto es así porque si una URL sirve contenido basado en cookies, podría estar cacheando contenido de un usuario autenticado, con información privada y luego servirla a anónimos.
Pero si hablamos de urls que siempre devuelven lo mismo, se puede pensar en una URL alternativa o una cabecera que hace que guarde en caché el contenido nuevo, sin leerlo nunca de la caché. Y sería muy útil para en lugar de purgar la caché, refrescarla con antelación cuando sabemos que ha cambiado.
En nginx esta función la realiza “cache_bypass” y se asigna a las variables que queramos. Si cualquiera de ellas devuelve algo distinto de vacío o cero, el contenido devuelto es nuevo. Si no se especifica “no_cache” la respuesta obtenida se guardará igualmente en la caché.
proxy_cache_bypass $bypass_request
Luego ya es lanzar un wget –mirror o similar con el método adecuado o cabeceras adecuadas, y nginx refrescará la caché.
Aunque igual es más sencillo purgarla por patrón y luego llenarla de nuevo consultando normalmente. Eso ya es cuestión de gustos y de las ventajas/inconvenientes para lo que queramos hacer exactamente.
Lo dejamos aquí por hoy. En el próximo post volvemos a la carga acelerando las páginas que requieren autenticación.
Nos vemos pronto!